Clonability of anti-counterfeiting printable graphical codes:
a machine learning approach

Code: PyTorch
If you have questions about our PyTorch code, please contact us.
The research was supported by the SNF project No. 200021_182063.
Abstract
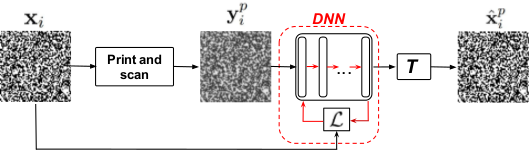
Fig.1: Training procedure based on training samples ![]() .
.
Attacks against PGC
The main goal of this work is to investigate the resistance of PGC to clonability attacks. The overwhelming majority of such attacks can be split into two main groups: (a) handcrafted attacks, which are based on the experience and knowhow of the attackers and (b) machine learning based attacks, which use training data to create clones of the original codes.
In our work, we focus on the investigation of machine learning based attacks due to the recent advent in the theory and practice of machine learning tools. Growing popularity and remarkable results of deep neural network (DNN) architectures in computer vision applications motivated us to investigate the clonability of PGC using these architectures trained for different classes of printers.
- we investigate the clonability of printable graphical codes using machine learning based attacks;
- we examine the proposed framework on real printed codes reproduced with 4 printers;
- we empirically demonstrate a possibility to sufficiently accurately clone the PGC from their printed counterparts in certain cases.
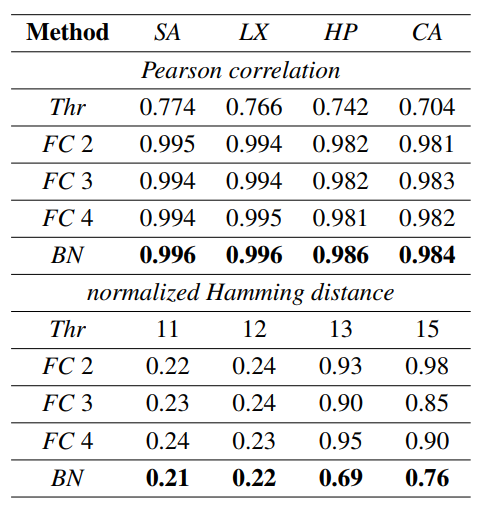
Table 1: Regeneration accuracy with respect to original codes.
- FC: fully connected DNN with 2, 3 and 4 hidden layers (hereafter referred to as FC 2, FC 3 and FC 4). The size of each layer equals to the input size.
- BN: ”bottleneck” model with 2 fully connected hidden layers of size 256 and 128 at the encoder and decoder parts and a latent representation of size 36.

To answer the question if the amount of errors in the BN regenerated codes can be noticed by the defender and how the BN results differ from the baseline estimation obtained via Thr method, we printed our estimated codes for both cases on the same printers with the same parameters as the original codes and after that we scanned them on the same scanner.
In our evaluation we use Pearson correlation between the originals and grey level printed codes. Additionally, we use normalized Hamming distance to measure the accuracy of the logical symbol estimation in the originals and binarized printed codes. Using these statistics, we compute the ROC curves based on the probability of correct detection ![]() and the probability of false acceptance
and the probability of false acceptance ![]() via:
via:
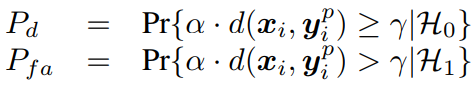
As it can be seen from the ROC curves illustrated in Fig. 3. the obtained results demonstrate the low resistance of the PGC based on DataMatrix modulation and similar codes to the machine learning based clonability attacks.
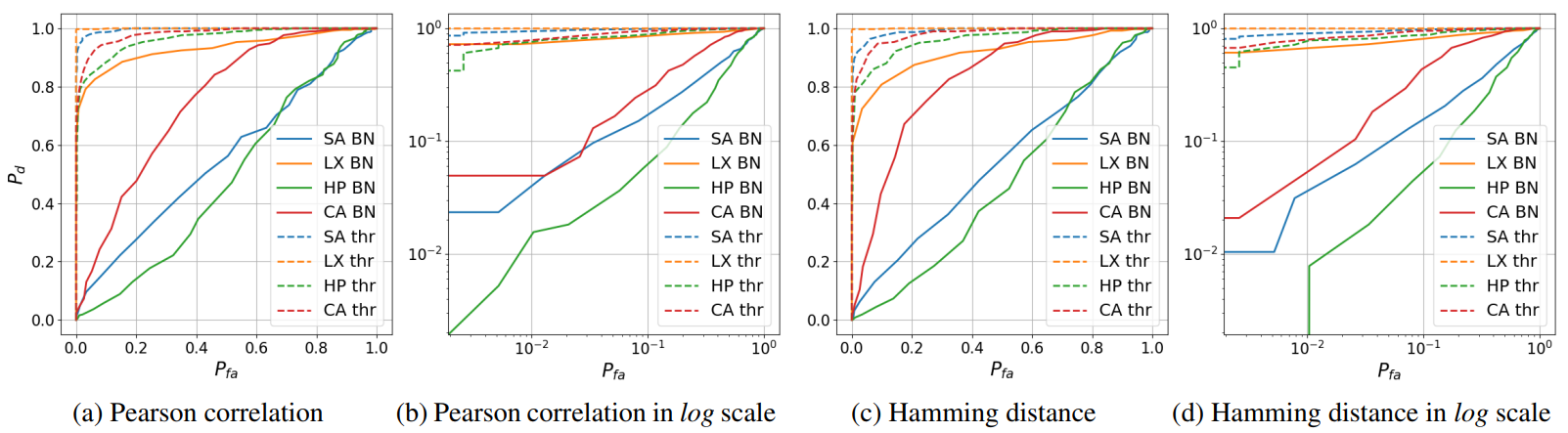
Fig.3: The ROC curves for Pearson correlation and Hamming distance between the original and fake printed codes estimated via BN and Thr methods.
Conclusions
In our work, we investigated the clonability of printable graphical codes using DataMatrix modulation typical for many PGC designs using machine learning based attacks. We tested the proposed framework with two different DNN architectures on real printed data. We empirically proved the possibility to accurately estimate the printable codes for high quality printers even from the relatively small training datasets. Based on the performed experiments and obtained results we can identify three main criteria for successful fake detection: (a) the printing quality, (b) the amount of errors in estimated codes and (c) the regularity of the estimated errors. The defenders should prefer average quality printers with a dot-gain sufficient to make regular errors in the originals estimation. Moreover, the results show that modern machine learning technologies make the printable graphical codes vulnerable to clonability attacks.
For future work, we aim at examining other types of graphical codes, at investigating the possibilities of mobile phones for the detection of fake codes and to compare the abilities of machine learning approaches versus hand-crafted attacks. Finally, we plan to consider GAN-like architectures to produce even more accurate fakes. The impact of the number of training examples and training from the original digital templates are also amongst our future priorities.
